Infinispan As Lucene Directory - Implementation Notes¶
- Table of contents
- Infinispan As Lucene Directory - Implementation Notes
Hibernate Search offers a Master/Slave set-up which gets along without infinispan and which allows to delegate all indexing operations from a slave application to a master. This master slave concept however has the drawback that the master index directory must be available to the slave application. The slave will copy the up-to-date index into its own index directory on a regular base. In the EDIT Platform we only can guarantee for the Ulteo based Editors that the master (cdmserver) index directory can be mounted by the slave. For other stand alone Editors running on various desktop computers this would be hard to achieve even if they are running in the same network. Each of these computers would have to be configured in order to mount a shared folder and this local mount folder must be configured in the EdiTor. Using infinispan might be the more elegant solution, though.
When using an Infinispan Directory the index is stored in memory and shared across multiple nodes. It is considered a single directory distributed across all participating nodes. If a node updates the index, all other nodes are updated as well. Updates on one node can be immediately searched for in the whole cluster.
As when using an IndexWriter on a filesystem based Directory, even on the clustered edition only one IndexWriter can be opened across the whole cluster.
Features¶
autodiscovery (feature of JGroups which is being used when Infinispan is running in clustered mode)
automatic failover and rebalancing
optionally transactions
can be backed by traditional storage solutions as fil esystem,
configurable consistency levels, synchronicity and guarantees-
total elasticity
Multi-tenancy (Multi-tenancy is achieved by namespacing. A single Infinispan cluster can have several named caches (attached to the same CacheManager), and different named caches can have duplicate keys. So this is, in effect, multi-tenancy for your key/value store.)
synchronous / asynchronous cache mode (Switching to asynchronous mode in API, Marshalling, or Replication causes loss of some consistency guarantees. The known problems are summarised here in the FAQ #_what_consistency_guarantees_do_i_have_with_different_asynchronous_processing_settings)
Which cache mode and manager for hibernate search in the EDIT Platform?¶
see http://infinispan.org/docs/5.3.x/user_guide/user_guide.html#_cache_modes_and_managing_indexes
What is the difference between a replicated cache and a distributed cache? ➜ #_what_is_the_difference_between_a_replicated_cache_and_a_distributed_cache
Distribution is a new cache mode in Infinispan, in addition to replication and invalidation. In a replicated cache all nodes in a cluster hold all keys i.e. if a key exists on one nodes, it will also exist on all other modes. In a distributed cache, a number of copies are maintained to provide redundancy and fault tolerance, however this is typically far fewer than the number of nodes in the cluster. A distributed cache provides a far greater degree of scalability than a replicated cache.
REPLICATION¶
In replication mode, each node can have its own local copy of the index (e.g.: FSDirectory). Drawback: when a new node is started it must receive an up to date copy of the index by using e.g.: rsync . This scenario is not recommended since it can cause inconsistencies between the nodes in the cluster.
Use a shared index:
- make sure that a single node is "in charge" of updating the index. The Hibernate Search reference documentation describes means to use a JMS queue or JGroups to send indexing tasks to a master node, This master/slave architecture can also be used without the infinispan directory provider.
- Hibernate search with infinispan: Again, using FSDirectory can be problematic due to locking issues, network problems and using it as a shared index might be a bad idea. Therefore better store the index in an Infinispan cache: have a look at the !InfinispanDirectoryProvider. Even when using an Infinispan directory it's still recommended to use the JMS Master/Slave or JGroups backend in hibernate.
DISTRIBUTION¶
Distributed mode is more powerful than simple replication since each data entry is spread out only to a fixed number of replicas thus providing resilience to server failures as well as scalability since the work done to store each entry is constant in relation to a cluster size. In distributed mode caches cluster together and expose a large memory heap.
if you are using DIST, synchronized communications are necessary (asynchronous is unofficially possible but will break api contracts)
you need to use a shared index and set indexLocalOnly to true.
CDM implementation notes¶
Scenario:
A central database server hosts the database for a cdm-server instance. Multiple Taxomic Editors partially Ulteo based, are also connecting and working on this central database. There is furthermore a data portal which is publishing this data and this web-application makes heavy use of the data store in the lucene index which is local to the file system of the cdm server ,and thus the cdm server is responsible for writing updates to this index. Therefore the cdm-server lucene index must always kept up to date with the changes applied by the editors. This is why updates of cdm entities, performed by the EdiTors, must and also cause updates of the lucene index in the cdm server. So the indexes must either be replicated or the cdm sever is the index master and the Editor are triggerting index updated in the cdm-server.
Requirements:
Updates to the shared index, master index must not be lost when an Application (the Taxonomic Editor) is offline, goes offline, network is lost, application crashes etc., operation system restarts, etc. A: In case of severe networking problems the connection to the central database will also be lost, so losing the infinispan cluster will only be a secondary problem without further consequences.
The Ulteo based EditTor is running in the same network as the cdm-server also the standalone Editors must be in the same network since they need direct access to the database server , so there should be no problem with autodiscovery. As last resort we could use in case of autodiscovery probelms the JDBCPING database based autodiscovery mechanism.
Notes:
- We must not confuse and mix up the different indexes which have the same instance name. The same cdm-server instance name may be used for example on the test server and production server. Solutions:
names the the index name must include the ip address or host name of the database server
different infinispan clusters for test, integration and production. (preferred solution?) On test and integration: configured as LOCAL clustering mode, in which case it will disable clustering features and serve as a cache for the index? Or we use no infinispan at all?
Infinispan will keep data in memory and thus will be consuming a significant amount of memory. It is also possible to offload part or most information to a CacheStore, such as plain file system, Amazon S3, Cassandra, Berkley DB or standard relational databases. You can configure it to have a CacheStore on each node or have a single centralized one shared by each node.
needs an additional maven dependency:
org.hibernate
hibernate-search-infinispan
4.3.0.Final
use the JMS Master/Slave or JGroups backend, because in Infinispan all nodes will share the same index and it is likely that IndexWriters being active on different nodes will try to acquire the lock on the same index.
deployment of freshly created lucene indexes should be possible by using
Infinispan_as_a_storage_for_Lucene_indexes.html]it is able to have Infinispan directly load data from an existing Lucene index into the grid. => A server dedicated to creating / preparing an index for deployment may abstain from using infinispan at all and could write into a ordinary lucene FS Directory. The content of this directory can then be deployed to the cluster.Do not forget to tune the chunk size, lucene segment size, JGroups and Networking stack for optimum performance
On Linux kernel parameters must be adjusted for JGroups:
sysctl -w net.core.rmem_max=26214400
sysctl -w net.core.wmem_max=655360
Benchmarking¶
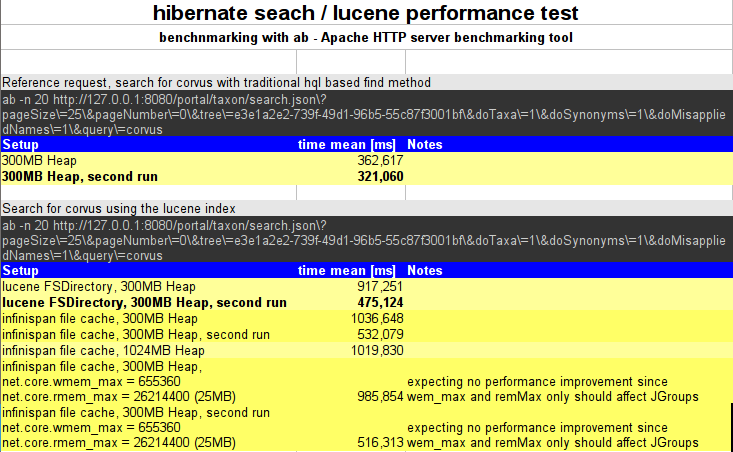
data in 2013-10-01 hibernate search - lucene performance tests.ods
Documentation¶
Infinispan as a storage for Lucene indexes also as Infinispan_as_a_storage_for_Lucene_indexes.pdf - outdated, but good overview!
Hibernate
Updated by Katja Luther about 2 years ago · 28 revisions